8 Hướng dẫn thực hành Orange data mining
Orange Data Mining, một công cụ trực quan hóa cho AI. Phụ lục này sẽ hướng dẫn bạn những thao tác cơ bản nhất để làm quen và bắt đầu sử dụng Orange cho việc phân tích dữ liệu và xây dựng các mô hình Trí tuệ nhân tạo (sơ khai). Hãy coi đây như một cuốn sổ tay dạng “mì ăn liền” để bạn có thể nhanh chóng bắt tay vào làm việc cới Orange.
8.1 P.1. Orange là gì và Cài đặt?
8.1.1 P.1.1. Orange Data Mining
Orange Data Mining (sau đây chúng ta sẽ gọi tắt là Orange) là một phần mềm miễn phí, mã nguồn mở mạnh mẽ giúp bạn phân tích dữ liệu và xây dựng các mô hình Trí tuệ Nhân tạo (AI) mà không cần viết một dòng code nào!
- Trực quan: Bạn sẽ làm việc bằng cách kéo thả các khối chức năng (gọi là “widget”) và nối chúng lại với nhau như chơi xếp hình.
- Dễ sử dụng: Phù hợp cho người mới bắt đầu, sinh viên, nhà phân tích kinh doanh, hoặc bất kỳ ai muốn khám phá dữ liệu và AI.
- Nhiều tính năng: Từ đọc dữ liệu, làm sạch, trực quan hóa, đến xây dựng các mô hình học máy phức tạp.
Trong giáo trình này, chúng ta sẽ sử dụng Orange để thực hành các khái niệm AI đã học.
8.1.2 P.1.2. Tải và Cài đặt Orange
Thực hiện theo các bước sau để cài đặt Orange trên máy tính của bạn:
- Truy cập trang chủ: Mở trình duyệt web và truy cập trang web chính thức của Orange Data Mining tại orangedatamining.com.
- Tải file cài đặt: Tìm đến mục “Download” trên trang chủ. Orange thường tự động phát hiện hệ điều hành của bạn hoặc bạn có thể chọn phiên bản phù hợp (Windows, macOS, hoặc Linux). Nhấn nút tải về phiên bản mới nhất và ổn định (thường là bản “Standalone Installer”).
- Chạy file cài đặt:
- Windows: Sau khi tải xong file
.exe, nhấp đúp vào file đó để khởi chạy trình cài đặt. - macOS: Sau khi tải xong file
.dmg, nhấp đúp để mở nó. Sau đó, kéo biểu tượng Orange vào thư mục Applications.
- Windows: Sau khi tải xong file
- Làm theo hướng dẫn: Thực hiện theo các bước hướng dẫn trên màn hình của trình cài đặt. Thông thường, bạn chỉ cần nhấn “Next” hoặc “Continue”, chấp nhận các điều khoản sử dụng, và chọn thư mục cài đặt (có thể để mặc định).
- (Hình P.2: Giao diện trình cài đặt Orange - Chụp một bước tiêu biểu trong quá trình cài đặt, ví dụ màn hình “Welcome to the Orange Setup Wizard” hoặc bước chọn thư mục cài đặt.)
- Hoàn tất: Sau khi quá trình cài đặt hoàn tất, bạn có thể tìm thấy biểu tượng Orange trong menu Start (Windows) hoặc trong thư mục Applications (macOS) và khởi chạy nó.
8.2 P.2. Khám phá Giao diện Orange
8.2.1 P.2.1. Màn hình Chào mừng và Khởi tạo
Khi bạn khởi chạy Orange lần đầu (hoặc khi bạn muốn tạo một project mới bằng cách chọn File -> New), bạn sẽ thấy màn hình Chào mừng (Welcome Screen).
- Tại đây, bạn có các tùy chọn chính:
- New: Tạo một workflow (quy trình làm việc) mới, bắt đầu với một Canvas trống.
- Open: Mở một workflow đã được lưu trước đó (file có đuôi
.ows). - Examples: Khám phá các workflow ví dụ có sẵn của Orange. Đây là một cách tuyệt vời để học hỏi cách sử dụng các widget khác nhau.
- Documentation, Tutorials: Truy cập tài liệu hướng dẫn chính thức và các bài học trực tuyến.
- (Hình P.3: Màn hình Welcome Screen của Orange, chỉ rõ các nút/khu vực “New”, “Open”, và “Examples”.)
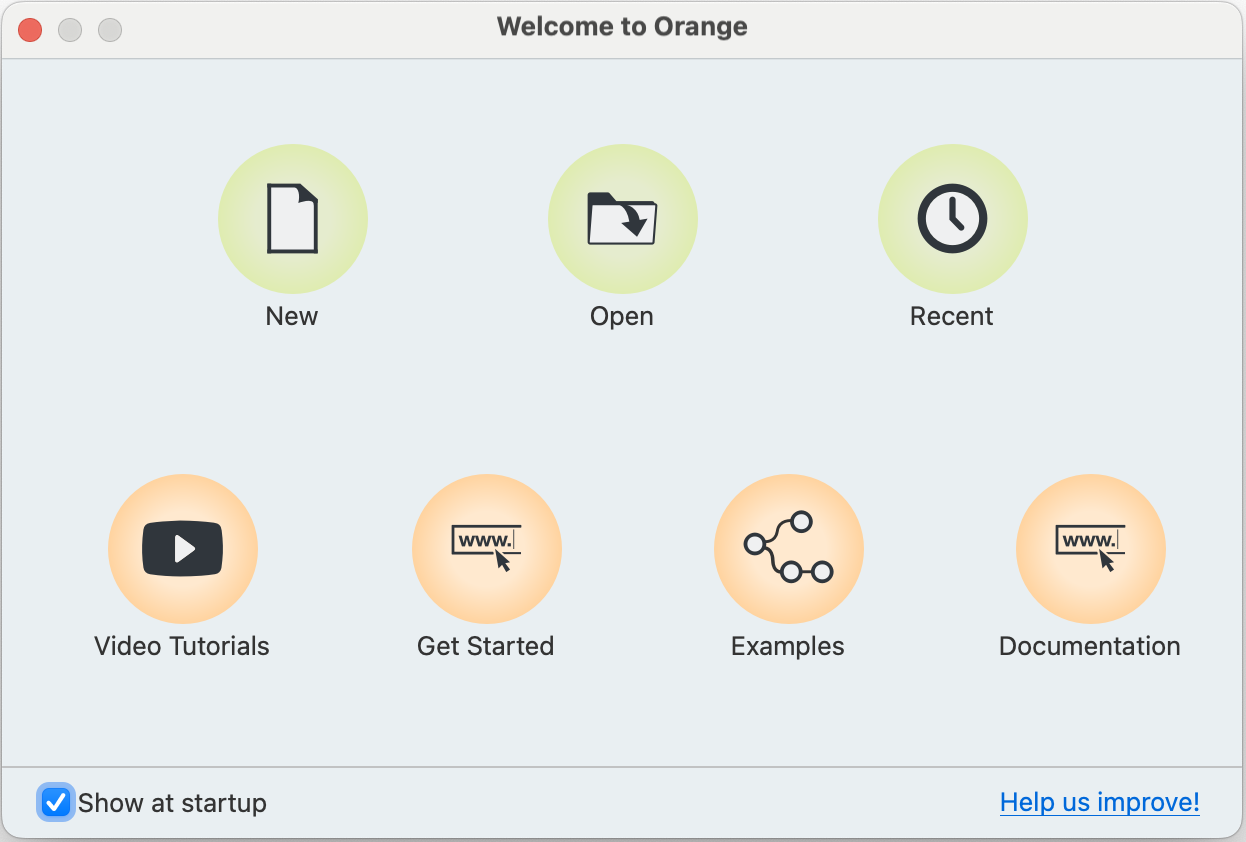
Để bắt đầu, hãy nhấp vào “New”.
8.2.2 P.2.2. Các Khu vực Chính:
Sau khi tạo một workflow mới, bạn sẽ thấy giao diện chính của Orange, bao gồm hai khu vực quan trọng:
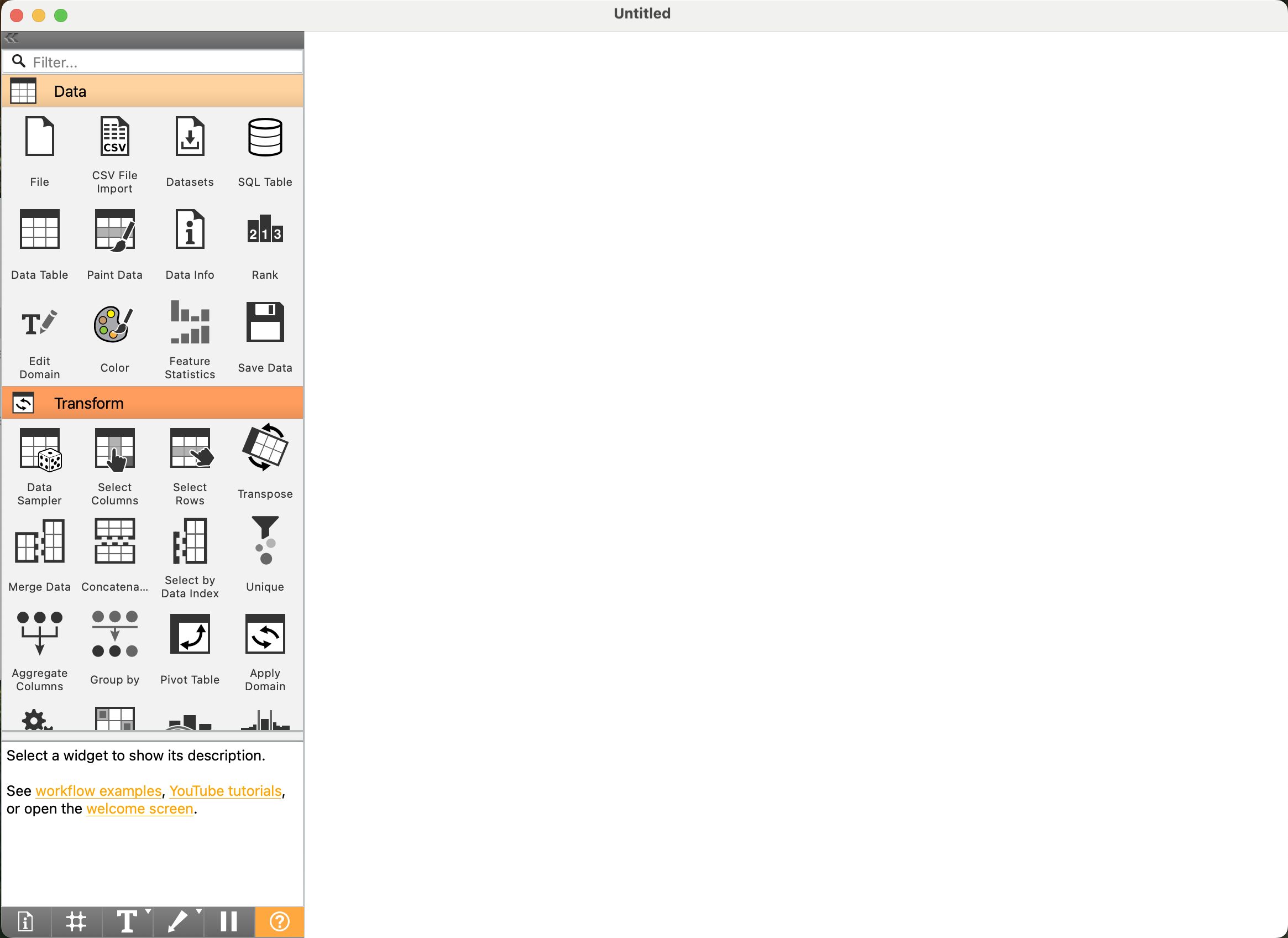
- Thanh Widgets (Widget Toolbox):
- Nằm ở phía bên trái màn hình.
- Đây là “hộp công cụ” chứa tất cả các khối chức năng (widgets) mà bạn sẽ sử dụng.
- Các widget được tổ chức thành các nhóm theo chức năng, ví dụ:
- Data: Các widget liên quan đến việc tải, xem, và tiền xử lý dữ liệu (ví dụ:
File,Data Table,Select Columns). - Visualize: Các widget để tạo biểu đồ và trực quan hóa dữ liệu (ví dụ:
Scatter Plot,Distributions,Box Plot). - Model: Các widget chứa các thuật toán Học máy (ví dụ:
Tree,Logistic Regression,Random Forest). - Evaluate: Các widget để đánh giá hiệu suất của mô hình (ví dụ:
Test & Score,Confusion Matrix). - Unsupervised: Các widget cho học không giám sát (ví dụ:
K-Means,PCA).
- Data: Các widget liên quan đến việc tải, xem, và tiền xử lý dữ liệu (ví dụ:
- Bạn có thể sử dụng ô tìm kiếm ở đầu Thanh Widgets để nhanh chóng tìm một widget cụ thể.
- Vùng làm việc (Canvas):
- Là không gian lớn, trống ở giữa màn hình.
- Đây là nơi bạn sẽ kéo các widget từ Thanh Widgets ra và kết nối chúng lại với nhau để xây dựng quy trình phân tích dữ liệu (workflow) của mình.
- (Hình P.4: Giao diện chính của Orange. Khoanh vùng và chú thích rõ “Thanh Widgets” (Widget Toolbox) ở bên trái và “Vùng làm việc” (Canvas) ở giữa.)
8.3 P.3. Workflow Đầu tiên: Tải, Xem và Trực quan hóa Dữ liệu Cơ bản
Hãy cùng xây dựng một workflow đơn giản để làm quen với các thao tác cơ bản.
8.3.1 P.3.1. Kéo và Thả Widgets:
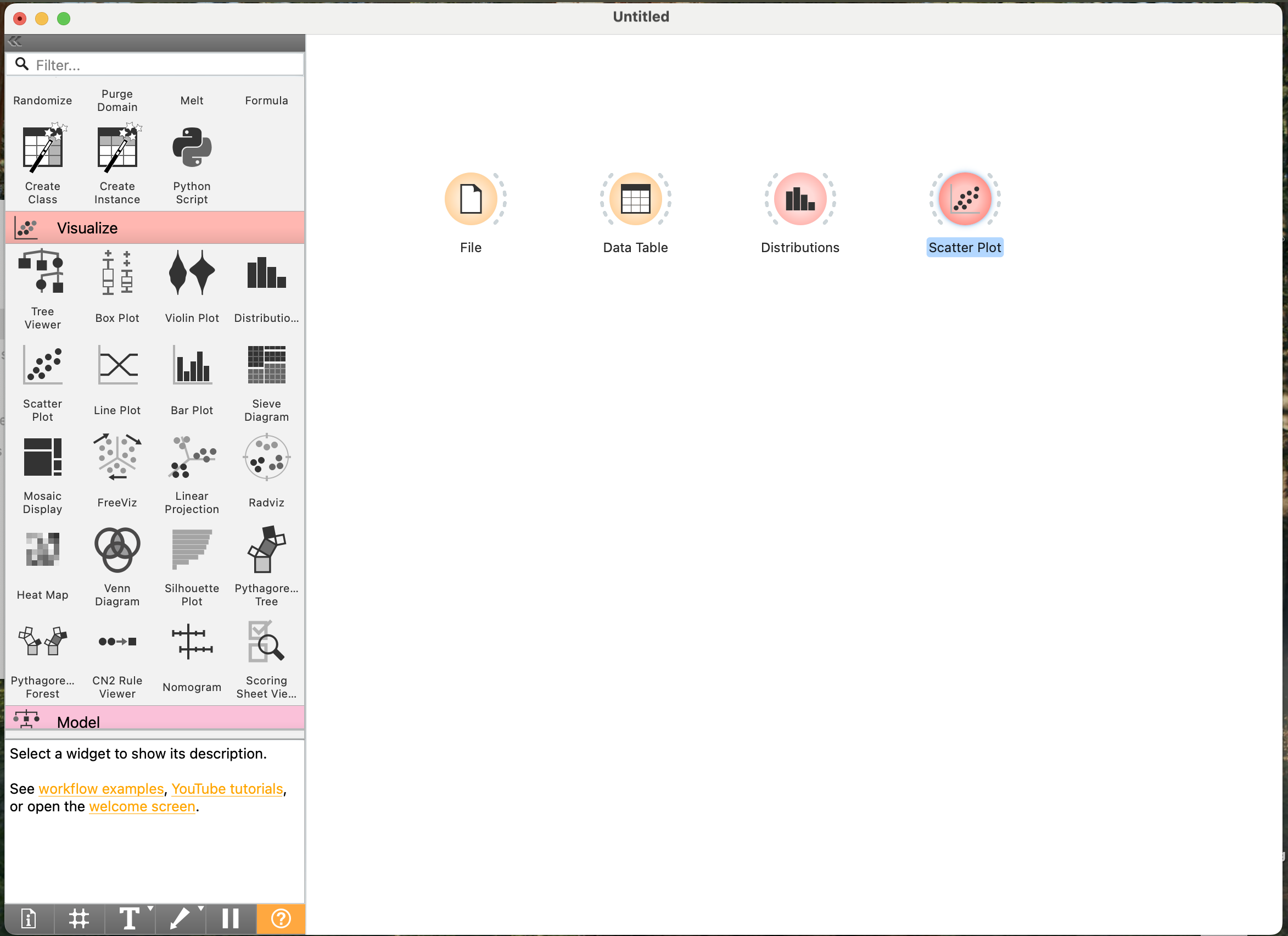
- Tìm Widget “File”: Trong Thanh Widgets, tìm nhóm Data. Bên trong đó, bạn sẽ thấy widget có tên là File (biểu tượng thường là một thư mục hoặc tệp).
- Kéo Widget “File” ra Canvas: Click chuột vào widget File hoặc kéo Widget này đến vị trí mong muốn vào vùng làm việc (Canvas) rồi thả chuột.
- (Hình P.5a: Con trỏ chuột đang kéo Widget “File” từ Thanh Widgets ra Canvas.)
- Tương tự, kéo các widget sau ra Canvas:
- Từ nhóm Data: Widget Data Table.
- Từ nhóm Visualize: Widget Distributions và Widget Scatter Plot.
- Lúc này trên Canvas của bạn sẽ có 4 widget này.
- (Hình P.5b: Canvas hiển thị 4 widget: File, Data Table, Distributions, Scatter Plot, chưa được kết nối.)
8.3.2 P.3.2. Nạp Dữ liệu từ File (Sử dụng Widget “File”)
Widget “File” dùng để tải dữ liệu từ nhiều nguồn khác nhau (file trên máy tính, URL, hoặc các bộ dữ liệu mẫu của Orange).
- Mở cấu hình Widget “File”: Nhấp đúp chuột vào widget File mà bạn vừa kéo ra Canvas. Một cửa sổ cấu hình sẽ xuất hiện.
- Chọn nguồn dữ liệu:
- Sử dụng bộ dữ liệu mẫu của Orange: Orange đi kèm với một số bộ dữ liệu mẫu rất tiện lợi để thực hành. Trong cửa sổ cấu hình, bạn có thể thấy một danh sách các file dữ liệu mẫu (ví dụ:
iris.tab,titanic.tab,housing.tab). Hãy chọniris.tab. - Tải file từ máy tính: Nếu bạn có file dữ liệu riêng (ví dụ file
.csv,.xlsx,.tab), nhấp vào biểu tượng thư mục (Folder icon) hoặc nút “Browse” để tìm và chọn file đó.
- Sử dụng bộ dữ liệu mẫu của Orange: Orange đi kèm với một số bộ dữ liệu mẫu rất tiện lợi để thực hành. Trong cửa sổ cấu hình, bạn có thể thấy một danh sách các file dữ liệu mẫu (ví dụ:
- Xem trước và Thông tin Dữ liệu: Sau khi chọn file, Orange sẽ hiển thị một phần dữ liệu xem trước và thông tin cơ bản về bộ dữ liệu như số lượng hàng (Instances), số lượng cột (Features).
- Thiết lập Vai trò cho các Cột (Quan trọng!):
- Ở phần dưới của cửa sổ cấu hình, bạn sẽ thấy danh sách các cột (Attributes) trong dữ liệu.
- Với mỗi cột, bạn cần xác định vai trò (Role) của nó:
- Feature (Thuộc tính): Đây là các biến đầu vào mà mô hình sẽ sử dụng để học hoặc phân tích. Hầu hết các cột dữ liệu của bạn sẽ là Feature.
- Target Variable (Biến Mục tiêu): Đây là biến mà bạn muốn mô hình dự đoán (trong Học có giám sát). Chỉ có thể có một biến Target. Nếu bạn đang làm học không giám sát hoặc chỉ muốn khám phá dữ liệu, bạn có thể không cần đặt biến Target.
- Meta (Thông tin bổ sung): Đây là các cột chứa thông tin bạn muốn giữ lại nhưng không muốn sử dụng trực tiếp làm Feature hoặc Target (ví dụ: ID khách hàng, tên).
- Nhấp vào tên cột, sau đó nhấp vào nút “Use as [Feature/Target/Meta/Skip]” để thay đổi vai trò của nó. “Skip” có nghĩa là bỏ qua cột đó.
- Đối với bộ dữ liệu
iris.tab:- Các cột
sepal length,sepal width,petal length,petal widthnên được đặt là Feature. - Cột
iris(tên loài hoa) nên được đặt là Target Variable (vì chúng ta thường muốn dự đoán loài hoa).
- Các cột
- Nhấn Apply hoặc OK sau khi hoàn tất cấu hình.
- (Hình P.6: Cửa sổ cấu hình của Widget “File” khi tải dữ liệu “iris.tab”. Chỉ rõ các khu vực: (1) Danh sách file mẫu / nút chọn file, (2) Khu vực xem trước dữ liệu, (3) Thông tin số dòng/cột, (4) Danh sách các cột và cách thay đổi vai trò (Role) của cột “iris” thành Target.)
8.3.3 P.3.3. Kết nối các Widgets:
Bây giờ chúng ta sẽ kết nối các widget lại với nhau để tạo thành một luồng xử lý dữ liệu. Dữ liệu sẽ chảy từ output (đầu ra) của widget này sang input (đầu vào) của widget khác.
- Nguyên tắc kết nối:
- Di chuột đến cạnh phải của một widget (nơi có output). Một hình bán nguyệt nhỏ hoặc một điểm nối sẽ xuất hiện.
- Nhấp và giữ chuột vào điểm nối output đó, sau đó kéo một đường thẳng đến cạnh trái của widget tiếp theo (nơi có input).
- Thả chuột để tạo kết nối. Đường nối sẽ xuất hiện.
- Thực hiện các kết nối sau:
- Kết nối từ output (Data) của widget File đến input (Data) của widget Data Table.
- Kết nối từ output (Data) của widget File đến input (Data) của widget Distributions.
- Kết nối từ output (Data) của widget File đến input (Data) của widget Scatter Plot.
- (Lưu ý: Một output có thể kết nối với nhiều input)
- (Hình P.7: Workflow hoàn chỉnh trên Canvas hiển thị 4 widget File, Data Table, Distributions, Scatter Plot đã được kết nối với nhau bằng các đường nối từ File đến 3 widget còn lại.)
- Khi kết nối thành công, đường nối thường sẽ dày hơn và widget nhận dữ liệu sẽ bắt đầu xử lý (có thể có thanh tiến trình nhỏ xuất hiện).
8.3.4 P.3.4. Xem Dữ liệu trong Bảng (Widget “Data Table”)
Widget “Data Table” cho phép bạn xem dữ liệu dưới dạng bảng, tương tự như một bảng tính.
- Mở Data Table: Nhấp đúp chuột vào widget Data Table đã được kết nối.
- Khám phá:
- Bạn sẽ thấy toàn bộ dữ liệu từ file
iris.tabđược hiển thị. - Bạn có thể nhấp vào tiêu đề cột để sắp xếp dữ liệu theo cột đó.
- Ở phía bên trái, có thể có các tùy chọn để hiển thị/ẩn thông tin bổ sung về các cột.
- (Hình P.8: Cửa sổ Widget “Data Table” hiển thị dữ liệu “iris.tab” dạng bảng. Có thể chỉ rõ cách sắp xếp theo một cột.)
- Bạn sẽ thấy toàn bộ dữ liệu từ file
- Đóng cửa sổ “Data Table” khi bạn đã xem xong.
8.3.5 P.3.5. Khám phá Phân phối Dữ liệu (Widget “Distributions”)
Widget “Distributions” giúp bạn xem biểu đồ phân phối của từng thuộc tính (feature) trong dữ liệu.
- Mở Distributions: Nhấp đúp chuột vào widget Distributions đã được kết nối.
- Khám phá:
- Ở danh sách bên trái (“Variables”), chọn một thuộc tính, ví dụ
sepal length(là biến số). Bạn sẽ thấy biểu đồ histogram của nó ở khu vực chính. - Chọn một thuộc tính danh mục (nếu có, ví dụ biến
irislà Target nhưng vẫn có thể xem phân phối của nó). Bạn sẽ thấy biểu đồ cột (bar chart) thể hiện tần suất của mỗi giá trị. - Bạn có thể chọn nhiều biến để so sánh phân phối của chúng.
- (Hình P.9: Cửa sổ Widget “Distributions”. Bên trái là danh sách biến, chọn “sepal length” và biểu đồ histogram tương ứng được hiển thị. Có thể thêm một ví dụ với biến “iris” để thấy bar chart.)
- Ở danh sách bên trái (“Variables”), chọn một thuộc tính, ví dụ
- Đóng cửa sổ “Distributions”.
8.3.6 P.3.6. Trực quan hóa Mối quan hệ (Widget “Scatter Plot”)
Widget “Scatter Plot” (Biểu đồ Tán xạ) rất hữu ích để xem mối quan hệ giữa hai biến số.
- Mở Scatter Plot: Nhấp đúp chuột vào widget Scatter Plot đã được kết nối.
- Khám phá:
- Chọn trục: Ở các mục “X-axis” và “Y-axis”, chọn các thuộc tính số bạn muốn vẽ. Ví dụ, chọn
sepal lengthcho trục X vàsepal widthcho trục Y. Bạn sẽ thấy các điểm dữ liệu được vẽ trên biểu đồ. - Tùy chọn hiển thị (Plot Properties):
- Color (Màu sắc): Chọn một biến danh mục (ví dụ:
iris- biến Target của chúng ta) để tô màu các điểm dữ liệu theo giá trị của biến đó. Điều này giúp xem liệu các lớp có tách biệt nhau dựa trên hai biến đang vẽ hay không. - Shape (Hình dạng), Size (Kích thước): Tương tự, bạn có thể thay đổi hình dạng hoặc kích thước của điểm dựa trên một biến khác.
- Show regressions lines: Có thể hiển thị đường hồi quy.
- Show legend: Hiển thị chú giải cho màu sắc/hình dạng.
- Color (Màu sắc): Chọn một biến danh mục (ví dụ:
- (Hình P.10: Cửa sổ Widget “Scatter Plot”. Đang hiển thị biểu đồ tán xạ giữa “sepal length” và “sepal width”, các điểm được tô màu theo biến “iris”. Chỉ rõ các khu vực chọn trục X, Y và tùy chọn Color.)
- Chọn trục: Ở các mục “X-axis” và “Y-axis”, chọn các thuộc tính số bạn muốn vẽ. Ví dụ, chọn
- Đóng cửa sổ “Scatter Plot”.
Bạn vừa hoàn thành workflow đầu tiên của mình trong Orange! Bạn đã học cách tải dữ liệu, kết nối các widget, xem dữ liệu dạng bảng và trực quan hóa nó bằng biểu đồ phân phối và biểu đồ tán xạ. Đây là những bước cơ bản và quan trọng trong mọi dự án phân tích dữ liệu.
8.4 P.4. Tiền xử lý Dữ liệu Cơ bản với Widgets
Dữ liệu thô thường không “sạch” và cần được chuẩn bị trước khi đưa vào mô hình hoặc phân tích sâu hơn. Orange cung cấp nhiều widget để thực hiện các tác vụ tiền xử lý.
8.4.1 P.4.1. Lựa chọn Cột (Widget “Select Columns”)
Đôi khi bộ dữ liệu của bạn có những cột không cần thiết hoặc bạn muốn thay đổi vai trò của chúng.
- Kéo Widget “Select Columns”: Từ nhóm Data, kéo widget Select Columns ra Canvas.
- Kết nối Dữ liệu: Nối output (Data) của widget chứa dữ liệu (ví dụ: “File”) vào input (Data) của “Select Columns”.
- Cấu hình: Nhấp đúp vào “Select Columns”.
- Bạn sẽ thấy các danh sách:
- Available Variables: Các cột hiện có trong dữ liệu.
- Features: Các cột được coi là thuộc tính đầu vào cho mô hình.
- Target Variable: Biến mục tiêu (nếu có).
- Meta Variables: Các cột thông tin bổ sung.
- Ignored Variables: Các cột bị bỏ qua.
- Cách di chuyển:
- Chọn một hoặc nhiều cột từ một danh sách.
- Sử dụng các nút mũi tên (->, <-, >>, <<) để di chuyển chúng sang danh sách mong muốn.
- Ví dụ: Nếu bạn muốn bỏ qua cột “ID_KhachHang”, hãy chọn nó từ “Available Variables” hoặc “Features” và chuyển nó sang “Ignored Variables”.
- (Hình P.11: Cửa sổ Widget “Select Columns”. Bên trái là “Available Variables”, bên phải là các khu vực “Features”, “Target”, “Meta”, “Ignored”. Minh họa việc một cột đang được chọn và các nút mũi tên để di chuyển.)
- Bạn sẽ thấy các danh sách:
- Nhấn Apply hoặc OK. Output của widget “Select Columns” sẽ là dữ liệu chỉ chứa các cột đã được bạn lựa chọn và thiết lập vai trò.
8.4.2 P.4.2. Lọc Hàng/Lấy Mẫu (Widget “Select Rows”, “Data Sampler”)
- Widget “Select Rows”: Dùng để lọc các hàng (bản ghi) dựa trên một hoặc nhiều điều kiện.
- Kết nối dữ liệu vào “Select Rows”.
- Nhấp đúp để mở cấu hình.
- Trong mục “Conditions”, bạn có thể thêm các điều kiện. Ví dụ:
age > 30 AND income < 50000.- (Hình P.12: Cửa sổ Widget “Select Rows” đang thiết lập một điều kiện lọc ví dụ, ví dụ: chọn cột “age”, toán tử “>”, giá trị “30”.)
- Output sẽ là dữ liệu chỉ chứa các hàng thỏa mãn điều kiện.
- Widget “Data Sampler”: Dùng để lấy một tập con (mẫu) từ dữ liệu.
- Kết nối dữ liệu vào “Data Sampler”.
- Nhấp đúp để mở cấu hình.
- Chọn phương pháp lấy mẫu:
- Fixed proportion of data: Lấy một tỷ lệ phần trăm cố định (ví dụ: 70% cho tập huấn luyện).
- Fixed sample size: Lấy một số lượng mẫu cố định.
- Cross Validation: (Sẽ tìm hiểu sau, dùng trong “Test & Score”).
- Output “Data Sample” là mẫu được lấy, và “Remaining Data” là phần còn lại.
8.4.3 P.4.3. Xử lý Giá trị Thiếu (Widget “Impute”)
Dữ liệu thiếu là vấn đề thường gặp. Widget “Impute” giúp bạn xử lý chúng.
- Kéo Widget “Impute”: Từ nhóm Data (hoặc Transform trong một số phiên bản cũ), kéo widget Impute ra Canvas.
- Kết nối Dữ liệu: Nối output của widget chứa dữ liệu có giá trị thiếu vào input của “Impute”.
- Cấu hình: Nhấp đúp vào “Impute”.
- Default method for continuous features: Chọn phương pháp điền giá trị cho các biến số liên tục (ví dụ: “Average/Most frequent”, “Median”, “Remove instances with missing values”).
- Default method for discrete features: Chọn phương pháp cho các biến danh mục (ví dụ: “Most frequent (mode)”, “Remove instances with missing values”).
- Bạn cũng có thể chọn phương pháp riêng cho từng cột cụ thể.
- (Hình P.13: Cửa sổ Widget “Impute”. Chỉ rõ các tùy chọn “Default method for continuous features” và “Default method for discrete features” đang được chọn.)
- Nhấn Apply hoặc OK. Output của “Impute” là dữ liệu đã được xử lý giá trị thiếu.
8.4.4 P.4.4. Rời rạc hóa Biến Liên tục (Widget “Discretize”)
Đôi khi, việc chuyển đổi một biến số liên tục (ví dụ: tuổi) thành một biến danh mục với các khoảng giá trị (ví dụ: “Trẻ”, “Trung niên”, “Già”) có thể hữu ích cho một số mô hình.
- Kéo Widget “Discretize”: Từ nhóm Transform (hoặc Data), kéo widget Discretize ra Canvas.
- Kết nối Dữ liệu: Nối dữ liệu vào “Discretize”.
- Cấu hình: Nhấp đúp vào “Discretize”.
- Chọn biến liên tục bạn muốn rời rạc hóa từ danh sách.
- Method: Chọn phương pháp chia khoảng:
- Equal-frequency discretization: Chia thành các khoảng có số lượng mẫu xấp xỉ bằng nhau.
- Equal-width discretization: Chia thành các khoảng có độ rộng bằng nhau.
- Entropy-MDL discretization: Một phương pháp dựa trên thông tin (thường dùng khi có biến Target).
- Nhập số khoảng (Number of intervals) mong muốn.
- (Hình P.14: Cửa sổ Widget “Discretize”. Một biến liên tục đang được chọn, phương pháp “Equal-frequency” và số khoảng “3” đang được thiết lập.)
- Nhấn Apply hoặc OK.
8.4.5 P.4.5. Sử dụng Widget “Preprocess” cho nhiều tác vụ
Widget “Preprocess” (nhóm Transform hoặc Data) cho phép bạn thực hiện một chuỗi các bước tiền xử lý một cách tiện lợi.
- Kết nối dữ liệu vào “Preprocess”.
- Nhấp đúp để mở cấu hình.
- Preprocessors: Bạn sẽ thấy một danh sách các bộ tiền xử lý có sẵn (ví dụ: Impute Missing Values, Continuize (bao gồm chuẩn hóa), Discretize, Randomize, Select Relevant Features).
- Thêm và Sắp xếp:
- Kéo các bộ tiền xử lý bạn muốn từ danh sách bên trái sang danh sách “Selected Preprocessors” bên phải.
- Thứ tự thực hiện sẽ từ trên xuống dưới. Bạn có thể kéo thả để thay đổi thứ tự.
- Nhấp vào một bộ tiền xử lý trong danh sách bên phải để cấu hình các tham số của nó (nếu có).
- (Hình P.15: Cửa sổ Widget “Preprocess”. Danh sách “Available Preprocessors” bên trái, danh sách “Selected Preprocessors” bên phải với một vài mục như “Impute Missing Values”, “Continuize”. Một bộ tiền xử lý đang được chọn để xem tham số.)
- Output của “Preprocess” là dữ liệu đã qua tất cả các bước tiền xử lý bạn chọn.
8.5 P.5. Xây dựng và Đánh giá Mô hình Học máy (Ví dụ Phân loại)
Đây là phần cốt lõi của Học máy. Chúng ta sẽ xây dựng một workflow để huấn luyện và đánh giá một mô hình phân loại.
8.5.1 P.5.1. Chuẩn bị Workflow:
- Nguồn Dữ liệu: Kéo widget File ra và tải một bộ dữ liệu phù hợp cho phân loại (ví dụ:
iris.tabhoặctitanic.tabtừ dữ liệu mẫu của Orange, đảm bảo đã đặt biến Target). - Widget Đánh giá: Kéo widget Test & Score từ nhóm Evaluate ra Canvas.
- Widget Mô hình: Kéo một hoặc nhiều widget mô hình phân loại từ nhóm Model ra Canvas. Ví dụ:
- Tree (Cây Quyết định)
- Logistic Regression
- Naive Bayes
8.5.2 P.5.2. Kết nối trong “Test & Score”:
Widget “Test & Score” là trung tâm để so sánh và đánh giá các mô hình.
- Kết nối Dữ liệu vào “Test & Score”:
- Nối output (Data) của widget File (hoặc output của widget tiền xử lý cuối cùng nếu có) vào input Data của widget Test & Score.
- Kết nối Mô hình vào “Test & Score”:
- Nối output (Learner) của widget Tree vào input Learner của widget Test & Score.
- Làm tương tự cho các widget mô hình khác (ví dụ: “Logistic Regression”, “Naive Bayes”) nếu bạn muốn so sánh chúng. Bạn có thể nối nhiều learner vào một widget “Test & Score”.
- (Hình P.16: Workflow trên Canvas. Widget “File” được nối với input “Data” của “Test & Score”. Các widget “Tree” và “Logistic Regression” được nối với input “Learner” của “Test & Score”.)
8.5.3 P.5.3. Cấu hình và Chạy “Test & Score”:
- Mở “Test & Score”: Nhấp đúp vào widget Test & Score.
- Phương pháp Đánh giá (Sampling):
- Chọn cách bạn muốn chia dữ liệu để huấn luyện và kiểm thử. Các lựa chọn phổ biến:
- Cross-validation: (Mặc định thường là 10-fold). Đây là phương pháp được khuyến nghị để có đánh giá ổn định. Bạn có thể thay đổi số fold.
- Random sampling: Chia ngẫu nhiên dữ liệu thành tập huấn luyện và tập kiểm thử theo một tỷ lệ (ví dụ: 70% train, 30% test).
- Test on train data: Đánh giá mô hình trên chính dữ liệu đã dùng để huấn luyện nó (thường cho kết quả quá lạc quan, dùng để kiểm tra underfitting/overfitting).
- Test on test data: Nếu bạn đã tự chia dữ liệu thành tập huấn luyện và kiểm thử riêng biệt bằng widget “Data Sampler” trước đó, bạn có thể cung cấp tập kiểm thử riêng vào một input khác của “Test & Score”.
- Chọn cách bạn muốn chia dữ liệu để huấn luyện và kiểm thử. Các lựa chọn phổ biến:
- Chọn Chỉ số Đánh giá:
- Ở bảng kết quả, bạn sẽ thấy các chỉ số đánh giá cho từng mô hình. Các chỉ số mặc định cho phân loại thường bao gồm:
- AUC (Area Under ROC Curve): Một thước đo tổng thể tốt.
- CA (Classification Accuracy): Độ chính xác.
- F1: Điểm F1.
- Precision: Độ chuẩn xác.
- Recall (Sensitivity): Độ phủ.
- Bạn có thể nhấp chuột phải vào tiêu đề bảng để chọn thêm hoặc bớt các chỉ số.
- (Hình P.17: Cửa sổ Widget “Test & Score”. Chỉ rõ khu vực chọn phương pháp “Sampling” (ví dụ: Cross-validation đang được chọn). Bảng kết quả hiển thị các mô hình (Tree, Logistic Regression) và các chỉ số AUC, CA, F1, Precision, Recall.)
- Ở bảng kết quả, bạn sẽ thấy các chỉ số đánh giá cho từng mô hình. Các chỉ số mặc định cho phân loại thường bao gồm:
- Quá trình đánh giá sẽ tự động chạy khi các kết nối được thiết lập.
8.5.4 P.5.4. Phân tích Kết quả:
Từ widget “Test & Score”, bạn có thể kết nối đến các widget khác để xem chi tiết hơn.
- Ma trận Nhầm lẫn (Widget “Confusion Matrix”):
- Kéo widget Confusion Matrix từ nhóm Evaluate ra Canvas.
- Nối output Evaluation Results của “Test & Score” vào input (Evaluation Results) của “Confusion Matrix”.
- Nhấp đúp vào “Confusion Matrix”.
- Bạn có thể chọn mô hình (Learner) từ danh sách để xem ma trận nhầm lẫn tương ứng của nó. Ma trận sẽ hiển thị số lượng True Positives, True Negatives, False Positives, False Negatives.
- (Hình P.18: Cửa sổ Widget “Confusion Matrix”. Một mô hình đang được chọn và ma trận 2x2 (hoặc NxN cho đa lớp) được hiển thị với các giá trị TP, TN, FP, FN.)
- Đường cong ROC (Widget “ROC Analysis”):
- Kéo widget ROC Analysis từ nhóm Evaluate ra Canvas.
- Nối output Evaluation Results của “Test & Score” vào input (Evaluation Results) của “ROC Analysis”.
- Nhấp đúp vào “ROC Analysis”.
- Biểu đồ sẽ hiển thị đường cong ROC cho từng mô hình (và giá trị AUC tương ứng). Đường cong càng gần góc trên bên trái, mô hình càng tốt.
- (Hình P.19: Cửa sổ Widget “ROC Analysis”. Hiển thị các đường cong ROC của nhiều mô hình trên cùng một biểu đồ, có chú giải và giá trị AUC.)
8.5.5 P.5.5. Trực quan hóa Mô hình (Ví dụ: Cây Quyết định):
Một số mô hình có thể được trực quan hóa để hiểu cách chúng đưa ra quyết định.
- Widget “Tree Viewer”:
- Kéo widget Tree Viewer từ nhóm Visualize ra Canvas.
- Để xem cây được huấn luyện trên toàn bộ dữ liệu đầu vào (không phải qua “Test & Score”): Nối output (Data) của “File” (hoặc widget tiền xử lý) vào input (Data) của “Tree”, và nối output (Learner) của “Tree” vào input (Learner) của “Tree Viewer”.
- Nhấp đúp vào “Tree Viewer”.
- Bạn sẽ thấy cấu trúc của cây quyết định, các nút chia tách, và các nút lá với dự đoán lớp.
- (Hình P.20: Cửa sổ Widget “Tree Viewer”. Hiển thị một cây quyết định trực quan với các nút và nhánh rõ ràng.)
8.6 P.6. Xây dựng và Đánh giá Mô hình Học máy (Ví dụ Hồi quy)
Quy trình tương tự như phân loại, nhưng sử dụng các widget mô hình hồi quy và các chỉ số đánh giá khác.
8.6.1 P.6.1. Chuẩn bị Workflow:
- Nguồn Dữ liệu: Dùng widget “File” để tải dữ liệu có biến Target là số liên tục (ví dụ: bộ
housing.tabmẫu của Orange). - Widget “Test & Score”.
- Widget Mô hình Hồi quy: Kéo các widget từ nhóm Model như:
- Linear Regression
- Random Forest Regression (Nếu Random Forest được kéo ra mà không có dữ liệu kết nối, nó có thể tự cấu hình cho hồi quy nếu Target là số)
- Regression Tree (Nếu Tree được kéo ra mà không có dữ liệu kết nối, nó có thể tự cấu hình cho hồi quy nếu Target là số)
8.6.2 P.6.2. Sử dụng Widget Mô hình Hồi quy và Kết nối:
Kết nối tương tự như P.5.2: “File” -> “Test & Score” (Data); các widget Mô hình Hồi quy -> “Test & Score” (Learner).
8.6.3 P.6.3. Kết nối và Cấu hình “Test & Score”:
- Nhấp đúp vào “Test & Score”.
- Phương pháp đánh giá (Sampling) tương tự như phân loại.
- Chọn Chỉ số Đánh giá Hồi quy:
- Các chỉ số phổ biến cho hồi quy sẽ được hiển thị:
- MSE (Mean Squared Error)
- RMSE (Root Mean Squared Error)
- MAE (Mean Absolute Error)
- R2 (R-squared)
- (Hình P.21: Cửa sổ “Test & Score”. Bảng kết quả hiển thị các mô hình hồi quy (Linear Regression, Random Forest) và các chỉ số MSE, RMSE, MAE, R2.)
- Các chỉ số phổ biến cho hồi quy sẽ được hiển thị:
8.6.4 P.6.4. Xem Dự đoán (Widget “Predictions”):
Widget “Predictions” cho phép bạn xem giá trị thực tế và giá trị dự đoán của mô hình.
- Kéo widget Predictions từ nhóm Evaluate ra Canvas.
- Nối output Evaluation Results của “Test & Score” (hoặc output “Data” của một mô hình cụ thể nếu bạn muốn xem dự đoán trên toàn bộ dữ liệu huấn luyện) vào input (Data) của “Predictions”.
- Nhấp đúp vào “Predictions”.
- Bảng sẽ hiển thị các cột dữ liệu gốc, cùng với các cột chứa giá trị dự đoán từ mỗi mô hình.
- (Hình P.22: Cửa sổ Widget “Predictions”. Hiển thị một vài hàng dữ liệu với cột giá trị Target thực tế và các cột giá trị dự đoán từ các mô hình hồi quy.)
8.7 P.7. Giới thiệu Học không giám sát (Ví dụ Phân cụm K-Means)
Học không giám sát không có biến Target. Chúng ta sẽ thử phân cụm.
8.7.1 P.7.1. Chuẩn bị Workflow:
- Nguồn Dữ liệu: Dùng widget “File” (ví dụ:
iris.tab. Để làm học không giám sát, chúng ta có thể dùng “Select Columns” để bỏ qua cột Target “iris” hoặc để Orange tự động bỏ qua nó khi đưa vào K-Means). - Widget Phân cụm: Kéo widget K-Means từ nhóm Unsupervised ra Canvas.
- Widget Trực quan hóa: Kéo widget Scatter Plot từ nhóm Visualize ra Canvas (để xem kết quả cụm).
8.7.2 P.7.2. Kết nối:
- Nối output (Data) của “File” (hoặc widget tiền xử lý) vào input (Data) của “K-Means”.
8.7.3 P.7.3. Cấu hình “K-Means”:
- Nhấp đúp vào widget K-Means.
- Number of clusters (k): Chọn số lượng cụm bạn muốn thuật toán tìm ra (ví dụ: 3 cho dữ liệu iris).
- Initialization: Phương pháp khởi tạo tâm cụm ban đầu (thường để mặc định “k-means++”).
- Max iterations: Số lần lặp tối đa.
- Nhấn Apply hoặc OK.
- (Hình P.23: Cửa sổ cấu hình của Widget “K-Means”. Đang thiết lập “Number of clusters” là 3.)
8.7.4 P.7.4. Trực quan hóa Kết quả Phân cụm:
- Nối output Data của “K-Means” vào input (Data) của “Scatter Plot”. Output này của “K-Means” là dữ liệu gốc đã được thêm một cột mới chứa nhãn cụm (“Cluster”) cho mỗi điểm dữ liệu.
- Nhấp đúp vào “Scatter Plot”.
- Chọn trục X, Y (ví dụ:
sepal length,sepal width). - Quan trọng: Trong phần Color (Màu sắc), chọn biến Cluster (biến mới do K-Means tạo ra).
- Các điểm dữ liệu trên biểu đồ sẽ được tô màu theo cụm mà chúng được gán vào.
- (Hình P.24: Widget “Scatter Plot” hiển thị các điểm dữ liệu của “iris.tab” (ví dụ: sepal length vs sepal width) được tô màu theo 3 cụm kết quả từ K-Means.)
8.8 P.8. Lưu, Mở và Chia sẻ Workflows
8.8.1 P.8.1. Lưu Workflow:
Sau khi xây dựng xong một workflow, bạn nên lưu nó lại.
- Chọn menu File -> Save hoặc File -> Save As…
- Đặt tên cho file workflow của bạn (Orange sẽ tự động thêm đuôi
.ows). - Chọn vị trí lưu và nhấn Save.
- (Hình P.25: Hộp thoại “Save Orange Workflow” (hoặc tương tự) đang hiển thị, cho phép nhập tên file và chọn vị trí lưu.)
8.8.2 P.8.2. Mở Workflow:
- Chọn menu File -> Open…
- Tìm đến file
.owsbạn muốn mở và chọn nó.
8.8.3 P.8.3. (Tùy chọn) Xuất hình ảnh Workflow:
Nếu bạn muốn chia sẻ hình ảnh của toàn bộ workflow trên Canvas: 1. Chọn menu File -> Print to PDF… (để lưu dưới dạng PDF) hoặc File -> Export as Image… (để lưu dưới dạng file ảnh như PNG, SVG).
8.9 P.9. Cài đặt và Sử dụng Add-ons (Ví dụ: Text Mining)
Orange có một hệ thống Add-ons (tiện ích mở rộng) cho phép bạn thêm các bộ widget chuyên biệt cho các tác vụ khác nhau.
8.9.1 P.9.1. Mở trình quản lý Add-ons:
- Chọn menu Options -> Add-ons…
8.9.2 P.9.2. Tìm và Cài đặt Add-on:
- Một cửa sổ sẽ xuất hiện liệt kê các add-on có sẵn.
- Tìm add-on bạn muốn cài đặt (ví dụ: gõ “Text” vào ô tìm kiếm để tìm “Text Mining” hoặc “Orange3-Text”).
- Chọn add-on đó và nhấn nút Install (hoặc đánh dấu vào ô checkbox bên cạnh rồi nhấn OK/Apply, tùy phiên bản Orange).
- Orange sẽ tải và cài đặt add-on. Quá trình này có thể mất vài phút.
- (Hình P.26: Cửa sổ quản lý Add-ons. Danh sách các add-on hiển thị, một add-on (ví dụ “Text Mining”) đang được chọn hoặc có nút “Install” bên cạnh.)
8.9.3 P.9.3. Khởi động lại Orange (nếu cần):
Một số add-on yêu cầu bạn khởi động lại Orange để các thay đổi có hiệu lực. Orange sẽ thông báo nếu cần.
8.9.4 P.9.4. Sử dụng Widget từ Add-on:
Sau khi cài đặt và khởi động lại (nếu cần), các widget mới từ add-on sẽ xuất hiện trong Thanh Widgets, thường trong một nhóm riêng mang tên add-on đó (ví dụ: nhóm “Text Mining”).
- Ví dụ với Text Mining:
- Kéo widget File ra, tải một file chứa dữ liệu văn bản (ví dụ: các bình luận của khách hàng, mỗi bình luận một dòng).
- Từ nhóm Text Mining, kéo widget Corpus ra Canvas. Kết nối “File” -> “Corpus”. Widget này dùng để tạo một tập hợp văn bản.
- Từ nhóm Text Mining, kéo widget Word Cloud ra Canvas. Kết nối “Corpus” -> “Word Cloud”.
- Nhấp đúp vào “Word Cloud” để xem đám mây từ, hiển thị các từ xuất hiện thường xuyên nhất.
- (Hình P.27: Một workflow đơn giản sử dụng Text Mining Add-on: File -> Corpus -> Word Cloud. Cửa sổ Word Cloud đang hiển thị một đám mây từ ví dụ.)
8.10 P.10. Mẹo và Nguồn Tham khảo Thêm
8.10.1 P.10.1. Một số Mẹo hữu ích:
- Nhấp chuột phải vào widget: Thường sẽ có các tùy chọn hữu ích như “Rename”, “Remove”, “Help”.
- Nhấp chuột phải vào đường nối: Có thể chọn “Remove Link”.
- Xem thông tin output của widget: Di chuột qua điểm output của một widget, một tooltip nhỏ sẽ hiện ra cho biết loại dữ liệu và số lượng mẫu.
- Sử dụng ô tìm kiếm widget: Gõ tên widget bạn cần vào ô tìm kiếm ở đầu Thanh Widgets.
8.10.2 P.10.2. Link đến Tài liệu Hướng dẫn Chính thức của Orange:
- Website chính thức: orangedatamining.com
- Tài liệu (Documentation): Thường có link trực tiếp trên website hoặc trong menu “Help” của Orange.
- Blog: Orange có một blog với nhiều bài viết hướng dẫn và ví dụ thú vị.